| Kategori: Vitenskapelige og akademiske publisering akademiske tidsskrifter: | |
| Kategori: Vitenskapelige og akademiske publisering akademiske tidsskrifter: | |
| Kategori: Vitenskapelige og akademiske publisering akademiske tidsskrifter: | |
| Algoritmisk tilstandsmaskin: Den algoritmiske tilstandsmaskinen ( ASM ) -metoden er en metode for å designe endelige tilstandsmaskiner (FSM) opprinnelig utviklet av Thomas E. Osborne ved University of California, Berkeley (UCB) siden 1960, introdusert for og implementert på Hewlett-Packard i 1968, formalisert og utvidet siden 1967 og skrevet om av Christopher R. Clare siden 1970. Det brukes til å representere diagrammer over digitale integrerte kretser. ASM-diagrammet er som et tilstandsdiagram, men mer strukturert og dermed lettere å forstå. Et ASM-diagram er en metode for å beskrive de sekvensielle operasjonene til et digitalt system. | |
| Algoritmer ulåst: Algorithms Unlocked er en bok av Thomas H. Cormen om de grunnleggende prinsippene og applikasjonene til datalgoritmer. Boken består av ti kapitler, og tar for seg temaene søk, sortering, grunnleggende grafalgoritmer, strengbehandling, grunnleggende kryptografi og datakomprimering, og en introduksjon til beregningsteorien. |  |
| Algoritmer og kombinatorikk: Algoritmer og kombinatorikk er en bokserie i matematikk, og spesielt i kombinatorikk og design og analyse av algoritmer. Den ble utgitt av Springer Science + Business Media, og ble grunnlagt i 1987. | |
| SWAT- og WADS-konferanser: WADS , Algorithms and Data Structures Symposium , er en internasjonal akademisk konferanse innen informatikk, med fokus på algoritmer og datastrukturer. WADS arrangeres hvert annet år, vanligvis i Canada og alltid i Nord-Amerika. Den holdes i veksling med søsterkonferansen, Scandinavian Symposium and Workshops on Algorithm Theory (SWAT) , som vanligvis holdes i Skandinavia og alltid i Nord-Europa. Historisk sett ble forhandlingene fra begge konferansene publisert av Springer Verlag gjennom deres forelesningsnotater i datavitenskapsserien. Springer fortsetter å publisere WADS-prosedyrer, men fra og med 2016 blir SWAT-prosedyrer nå publisert av Dagstuhl gjennom Leibniz International Proceedings in Informatics. | |
| SWAT- og WADS-konferanser: WADS , Algorithms and Data Structures Symposium , er en internasjonal akademisk konferanse innen informatikk, med fokus på algoritmer og datastrukturer. WADS arrangeres hvert annet år, vanligvis i Canada og alltid i Nord-Amerika. Den holdes i veksling med søsterkonferansen, Scandinavian Symposium and Workshops on Algorithm Theory (SWAT) , som vanligvis holdes i Skandinavia og alltid i Nord-Europa. Historisk sett ble forhandlingene fra begge konferansene publisert av Springer Verlag gjennom deres forelesningsnotater i datavitenskapsserien. Springer fortsetter å publisere WADS-prosedyrer, men fra og med 2016 blir SWAT-prosedyrer nå publisert av Dagstuhl gjennom Leibniz International Proceedings in Informatics. | |
| Algoritmer for utvinning og isolasjon som utnytter semantikk: I datavitenskap er Algorithms for Recovery and Isolation Exploiting Semantics , eller ARIES , en gjenopprettingsalgoritme designet for å fungere med en no-force, stjele databasetilnærming; den brukes av IBM DB2, Microsoft SQL Server og mange andre databasesystemer. IBM-stipendiat Dr. C. Mohan er den viktigste oppfinneren av ARIES-familien til algo. | |
| Algoritmer for utvinning og isolasjon som utnytter semantikk: I datavitenskap er Algorithms for Recovery and Isolation Exploiting Semantics , eller ARIES , en gjenopprettingsalgoritme designet for å fungere med en no-force, stjele databasetilnærming; den brukes av IBM DB2, Microsoft SQL Server og mange andre databasesystemer. IBM-stipendiat Dr. C. Mohan er den viktigste oppfinneren av ARIES-familien til algo. | |
| Avansert hjerte livsstøtte: Avansert hjertestøtte , eller avansert kardiovaskulær livsstøtte , ofte referert til av akronymet, " ACLS ", refererer til et sett med kliniske algoritmer for akutt behandling av hjertestans, hjerneslag, hjerteinfarkt og andre livstruende kardiovaskulære nødsituasjoner. Utenfor Nord-Amerika brukes Advanced Life Support (ALS). | 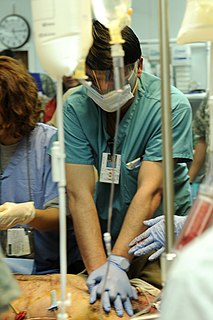 |
| Automatisert planlegging og planlegging: Automatisert planlegging og planlegging , noen ganger betegnet som bare AI-planlegging , er en gren av kunstig intelligens som gjelder realisering av strategier eller handlingssekvenser, vanligvis for utførelse av intelligente agenter, autonome roboter og ubemannede kjøretøy. I motsetning til klassiske kontroll- og klassifiseringsproblemer, er løsningene komplekse og må oppdages og optimaliseres i flerdimensjonalt rom. Planlegging er også relatert til beslutningsteori. | |
| Sinus: I matematikk er sinus en trigonometrisk funksjon av en vinkel. Sinusen til en spiss vinkel er definert i sammenheng med en rett trekant: for den angitte vinkelen er det forholdet mellom lengden på siden som er motsatt den vinkelen, og lengden på den lengste siden av trekanten. For en vinkel , er sinusfunksjonen betegnet ganske enkelt som . |  |
| Algoritmer for beregning av varians: Algoritmer for beregning av varians spiller en viktig rolle i beregningsstatistikk. En nøkkelproblematikk i utformingen av gode algoritmer for dette problemet er at formler for avviket kan innebære kvadratsummer, noe som kan føre til numerisk ustabilitet, samt til aritmetisk overløp når man arbeider med store verdier. | |
| Årsaksslutning: Årsaksslutning er prosessen med å bestemme den uavhengige, faktiske effekten av et bestemt fenomen som er en komponent i et større system. Hovedforskjellen mellom kausal inferens og assosiasjon av assosiasjon er at kausal inferens analyserer responsen til en effektvariabel når en årsak til effektvariabelen endres. Vitenskapen om hvorfor ting skjer kalles etiologi. Årsaksslutning sies å gi bevis for årsakssammenheng teoretisert av årsaksbegrunnelse. | |
| Klynging av datastrøm: I datavitenskap er datastrømsklynging definert som klynging av data som kommer kontinuerlig som telefonposter, multimediedata, økonomiske transaksjoner etc. Datastrømsklynging studeres vanligvis som en streamingalgoritme og målet er gitt en sekvens av poeng, å konstruere en god klynging av strømmen, ved å bruke en liten mengde minne og tid. | |
| Fargekartlegging: Fargekartlegging (fotografering) er en funksjon som kartlegger (transformerer) fargene på ett (kilde) bilde til fargene på et annet (mål) bilde. En fargekartlegging kan refereres til som algoritmen som resulterer i kartleggingsfunksjonen eller algoritmen som forvandler bildefargene. Fargekartlegging kalles også noen ganger fargeoverføring, eller når gråtonebilder er involvert, lysstyrkeoverføringsfunksjon (BTF) ; det kan også kalles fotometrisk kamerakalibrering eller radiometrisk kamerakalibrering . |  |
| Kombinatorisk optimalisering: Kombinatorisk optimalisering er et underfelt av matematisk optimalisering som er relatert til operasjonsforskning, algoritmeteori og beregningskompleksitetsteori. Den har viktige applikasjoner innen flere felt, inkludert kunstig intelligens, maskinlæring, auksjonsteori, programvareteknikk, anvendt matematikk og teoretisk informatikk. |  |
| Transitiv lukking: I matematikk er den transitive lukkingen av en binær relasjon R på et sett X den minste relasjonen på X som inneholder R og er transitiv. For endelige sett kan "minste" tas i sin vanlige forstand, å ha færrest beslektede par; for uendelige sett er det den unike minimale transitive supersettet av R. | |
| Problem med tilfredshet av begrensning: Problemer med tilfredshet ( CSP ) er matematiske spørsmål definert som et sett med objekter hvis tilstand må tilfredsstille en rekke begrensninger eller begrensninger. CSP-er representerer enhetene i et problem som en homogen samling av begrensede begrensninger over variabler, som løses ved hjelp av begrensningstilfredshetsmetoder. CSP er gjenstand for intens forskning innen både kunstig intelligens og operasjonsforskning, siden regelmessigheten i formuleringen deres gir et felles grunnlag for å analysere og løse problemer for mange tilsynelatende ikke-relaterte familier. CSP viser ofte høy kompleksitet, og krever at en kombinasjon av heuristikk og kombinatoriske søkemetoder løses på en rimelig tid. Constraint Programming (CP) er forskningsfeltet som spesielt fokuserer på å takle denne typen problemer. I tillegg er boolsk tilfredsstillelsesproblem (SAT), tilfredshetsmodulteoriene (SMT), blandet heltallsprogrammering (MIP) og svarsettprogrammering (ASP) alle forskningsfelt som fokuserer på oppløsningen av bestemte former for problemet med begrensningstilfredshet. | |
| Problem med tilfredshet av begrensning: Problemer med tilfredshet ( CSP ) er matematiske spørsmål definert som et sett med objekter hvis tilstand må tilfredsstille en rekke begrensninger eller begrensninger. CSP-er representerer enhetene i et problem som en homogen samling av begrensede begrensninger over variabler, som løses ved hjelp av begrensningstilfredshetsmetoder. CSP er gjenstand for intens forskning innen både kunstig intelligens og operasjonsforskning, siden regelmessigheten i formuleringen deres gir et felles grunnlag for å analysere og løse problemer for mange tilsynelatende ikke-relaterte familier. CSP viser ofte høy kompleksitet, og krever at en kombinasjon av heuristikk og kombinatoriske søkemetoder løses på en rimelig tid. Constraint Programming (CP) er forskningsfeltet som spesielt fokuserer på å takle denne typen problemer. I tillegg er boolsk tilfredsstillelsesproblem (SAT), tilfredshetsmodulteoriene (SMT), blandet heltallsprogrammering (MIP) og svarsettprogrammering (ASP) alle forskningsfelt som fokuserer på oppløsningen av bestemte former for problemet med begrensningstilfredshet. | |
| Kontekstuell bildeklassifisering: Kontekstuell bildeklassifisering , et tema for mønstergjenkjenning i datasyn, er en tilnærming til klassifisering basert på kontekstuell informasjon i bilder. "Kontekstuell" betyr at denne tilnærmingen fokuserer på forholdet til nærliggende piksler, som også kalles nabolag. Målet med denne tilnærmingen er å klassifisere bildene ved hjelp av kontekstuell informasjon. | |
| Kontrastsett læring: Kontrastsett læring er en form for assosiasjon regelinnlæring som søker å identifisere meningsfulle forskjeller mellom separate grupper ved å reversere de viktigste prediktorene som identifiserer for hver enkelt gruppe. For eksempel, gitt et sett med attributter for en gruppe studenter, ville en elev i kontrastsett identifisere de kontrasterende funksjonene mellom studenter som søker bachelorgrader og de som jobber mot PhD-grader. | |
| Forsterkningslæring: Forsterkningslæring ( RL ) er et område innen maskinlæring som er opptatt av hvordan intelligente agenter burde iverksette tiltak i et miljø for å maksimere forestillingen om kumulativ belønning. Forsterkningslæring er en av tre grunnleggende maskinlæringsparadigmer, ved siden av veiledet læring og uten tilsyn. | |
| Korrelasjonsklynging: Klynging er problemet med partisjonering av datapunkter i grupper basert på deres likhet. Korrelasjonsklynging gir en metode for å gruppere et sett med objekter i det optimale antall klynger uten å spesifisere dette tallet på forhånd. | |
| Syklusdeteksjon: I informatikk er syklusdeteksjon eller syklusfunn det algoritmiske problemet med å finne en syklus i en sekvens av itererte funksjonsverdier. | |
| Dataanalyse: Dataanalyse er en prosess med inspeksjon, rensing, transformering og modellering av data med det formål å oppdage nyttig informasjon, informere konklusjoner og støtte beslutningstaking. Dataanalyse har flere fasetter og tilnærminger, som omfatter forskjellige teknikker under en rekke navn, og brukes i forskjellige forretnings-, vitenskaps- og samfunnsvitenskapelige domener. I dagens næringsliv spiller dataanalyse en rolle i å ta beslutninger mer vitenskapelig og hjelpe bedrifter til å operere mer effektivt. |  |
| Klynging av datastrøm: I datavitenskap er datastrømsklynging definert som klynging av data som kommer kontinuerlig som telefonposter, multimediedata, økonomiske transaksjoner etc. Datastrømsklynging studeres vanligvis som en streamingalgoritme og målet er gitt en sekvens av poeng, å konstruere en god klynging av strømmen, ved å bruke en liten mengde minne og tid. | |
| Demosaicing: En demosaiseringsalgoritme er en digital bildeprosess som brukes til å rekonstruere et fullfargebilde fra de ufullstendige fargeprøver som sendes ut fra en bildesensor overlappet med et fargefilterarray (CFA). Det er også kjent som CFA-interpolering eller fargegjenoppbygging . | |
| Hjertefeil: Hjertesvikt ( HF ), også kjent som kongestiv hjertesvikt ( CHF ), ( kongestiv ) hjertesvikt ( CCF ) og decompensatio cordis , er når hjertet ikke er i stand til å pumpe tilstrekkelig til å opprettholde blodstrømmen for å dekke kroppsvevets behov for metabolisme. Tegn og symptomer på hjertesvikt inkluderer ofte kortpustethet, overdreven tretthet og hevelse i bena. Kortpustethet er vanligvis verre ved trening eller mens du ligger, og kan vekke personen om natten. En begrenset evne til å trene er også et vanlig trekk. Brystsmerter, inkludert angina, oppstår vanligvis ikke på grunn av hjertesvikt. |  |
| Distribuert begrensningsoptimalisering: Distribuert begrensningsoptimalisering er den distribuerte analoge til begrensningsoptimaliseringen. En DCOP er et problem der en gruppe agenter fordelt må velge verdier for et sett med variabler slik at kostnadene for et sett med begrensninger over variablene minimeres. | |
| Dokumentklynging: Dokumentklynging er anvendelsen av klyngeanalyse på tekstdokumenter. Den har applikasjoner innen automatisk dokumentorganisering, emneutvinning og rask informasjonsinnhenting eller filtrering. | |
| Analyse av dokumentoppsett: I datasyn eller naturlig språkbehandling er dokumentoppsettanalyse prosessen med å identifisere og kategorisere regionene som er av interesse for det skannede bildet av et tekstdokument. Et lesesystem krever segmentering av tekstsoner fra ikke-tekstlige og ordningen i riktig leserekkefølge. Oppdagelse og merking av de forskjellige sonene som teksttekst, illustrasjoner, matematiske symboler og tabeller innebygd i et dokument kalles geometrisk layoutanalyse . Men tekstsoner spiller forskjellige logiske roller inne i dokumentet, og denne typen semantisk merking er omfanget av den logiske layoutanalysen . | |
| Kantfarging: I grafteori er en kantfarging av en graf en tildeling av "farger" til kantene på grafen slik at ingen to innfallende kanter har samme farge. For eksempel viser figuren til høyre en kantfarging av en graf med fargene rød, blå og grønn. Kantfarging er en av flere forskjellige typer graffarging. Kantfargeproblemet spør om det er mulig å fargelegge kantene på en gitt graf ved å bruke maksimalt k forskjellige farger, for en gitt verdi på k , eller med færrest mulig farger. Det minste nødvendige antall farger for kantene til en gitt graf kalles grafens kromatiske indeks . For eksempel kan kantene på grafen i illustrasjonen være farget med tre farger, men kan ikke farges med to farger, så grafen som vises har kromatisk indeks tre. |  |
| Heltalsfaktorisering: I tallteori er heltallfaktorisering nedbrytningen av et sammensatt tall til et produkt med mindre heltall. Hvis disse faktorene er ytterligere begrenset til primtall, kalles prosessen primfaktorisering . | |
| Ureduserbart polynom: I matematikk er et irredusibelt polynom , grovt sett, et polynom som ikke kan regnes med i produktet av to ikke-konstante polynomer. Egenskapen til irreduserbarhet avhenger av arten av koeffisientene som er akseptert for de mulige faktorene, det vil si feltet eller ringen som koeffisientene til polynomet og dets mulige faktorer skal tilhøre. For eksempel er polynomet x 2 - 2 et polynom med heltallskoeffisienter, men ettersom hvert heltall også er et reelt tall, er det også et polynom med reelle koeffisienter. Det er irredusibelt hvis det betraktes som et polynom med heltallskoeffisienter, men det er faktorer som hvis det betraktes som et polynom med reelle koeffisienter. En sier at polynomet x 2 - 2 er irredusibelt over heltallene, men ikke over realene. | |
| Euklidisk minimum spennende tre: Det euklidiske minimumspennende treet eller EMST er et minimumspennende tre av et sett med n- punkter i planet, der vekten av kanten mellom hvert par av punkter er den euklidiske avstanden mellom disse to punktene. I enklere termer kobler en EMST et sett med prikker ved hjelp av linjer slik at den totale lengden på alle linjene minimeres, og enhver prikk kan nås fra andre ved å følge linjene. |  |
| Kapasitert minimum spennende tre: Capacitated minimum spanning tree er et minimalt kostnadsomfattende tre i en graf som har en angitt rotnode og tilfredsstiller kapasitetsbegrensningen . Kapasitetsbegrensningen sørger for at alle undertrær hender på rotnoden har ikke mer enn noder. Hvis treknutene har vekter, kan kapasitetsbegrensningen tolkes som følger: summen av vekter i et hvilket som helst undertrær bør ikke være større enn . Kantene som forbinder underbildene til rotnoden kalles porter . Å finne den optimale løsningen er NP-vanskelig. |  |
| Minimum spennende tre: Et minimumsstreet ( MST ) eller minimumsvektstreet er en delmengde av kantene til en tilkoblet, kantvektet, ikke-rettet graf som forbinder alle toppene sammen, uten noen sykluser og med den minste mulige totale kantvekten. Det vil si at det er et spennende tre som har en så liten kantvekt som mulig. Mer generelt har en hvilken som helst kantvektet, ikke-rettet graf et minimum som spenner over skog , som er en forening av de minste spennende trærne for de tilkoblede komponentene. | |
| Fingeravtrykk: Et fingeravtrykk er et inntrykk som etterlates av friksjonsryggene til en menneskelig finger. Gjenoppretting av delvise fingeravtrykk fra et åsted er en viktig metode for rettsmedisinsk vitenskap. Fuktighet og fett på en finger resulterer i fingeravtrykk på overflater som glass eller metall. Bevisst inntrykk av hele fingeravtrykk kan fås med blekk eller andre stoffer som overføres fra toppene av friksjonsryggene på huden til en glatt overflate som papir. Fingeravtrykksopptegnelser inneholder normalt inntrykk fra puten på den siste skjøten av fingre og tommelen, selv om fingeravtrykkkort også vanligvis registrerer deler av nedre leddområder av fingrene. |  |
| Formell konseptanalyse: Formell konseptanalyse ( FCA ) er en prinsipiell måte å utlede et konsepthierarki eller formell ontologi fra en samling objekter og deres egenskaper. Hvert konsept i hierarkiet representerer objektene som deler et sett med egenskaper; og hvert delkonsept i hierarkiet representerer en delmengde av objektene i konseptene over det. Begrepet ble introdusert av Rudolf Wille i 1981, og bygger på den matematiske teorien om gitter og bestilte sett som ble utviklet av Garrett Birkhoff og andre på 1930-tallet. | |
| Bevegelsesgjenkjenning: Gestgjenkjenning er et tema innen informatikk og språkteknologi med mål om å tolke menneskelige gester via matematiske algoritmer. Det er en underdisiplin av datasyn. Bevegelser kan stamme fra enhver kroppslig bevegelse eller tilstand, men stammer ofte fra ansiktet eller hånden. Nåværende fokus i feltet inkluderer følelsesgjenkjenning fra ansikts- og håndbevegelsesgjenkjenning. Brukere kan bruke enkle bevegelser for å kontrollere eller samhandle med enheter uten å berøre dem fysisk. Mange tilnærminger har blitt gjort ved hjelp av kameraer og algoritmer for datasyn for å tolke tegnspråk. Imidlertid er identifikasjon og gjenkjenning av holdning, gangart, nærhet og menneskelig atferd også gjenstand for bevegelsesgjenkjenningsteknikker. Bevisstelsesgjenkjenning kan sees på som en måte for datamaskiner å begynne å forstå menneskets kroppsspråk, og dermed bygge en rikere bro mellom maskiner og mennesker enn primitive tekstbrukergrensesnitt eller til og med GUIer, som fremdeles begrenser flertallet av input til tastatur og mus og samhandler naturlig uten noen mekaniske enheter. Ved å bruke begrepet bevegelsesgjenkjenning er det mulig å peke en finger på dette punktet vil bevege seg tilsvarende. Dette kan gjøre konvensjonelle innganger på enheter slike og til og med overflødige. |  |
| Global belysning: Global illumination ( GI ), eller indirekte belysning , er en gruppe algoritmer som brukes i 3D datagrafikk som er ment å legge til mer realistisk belysning til 3D-scener. Slike algoritmer tar ikke bare hensyn til lyset som kommer direkte fra en lyskilde, men også påfølgende tilfeller der lysstråler fra samme kilde reflekteres av andre overflater i scenen, enten reflekterende eller ikke. |  |
| Graffarging: I grafteori er graffarging et spesielt tilfelle av grafmerking. det er en tildeling av etiketter som tradisjonelt kalles "farger" til elementer i en graf som er underlagt visse begrensninger. I sin enkleste form er det en måte å fargelegge hjørnene i en graf slik at ingen to tilstøtende hjørner har samme farge; dette kalles toppunktfarging . På samme måte tildeler en kantfarging en farge til hver kant slik at ingen to tilstøtende kanter har samme farge, og en ansiktsfarging av en plan graf tildeler en farge til hvert ansikt eller region, slik at ingen ansikter som deler en grense har samme farge. |  |
| Bildekomprimering: Bildekomprimering er en type datakomprimering som brukes på digitale bilder, for å redusere kostnadene for lagring eller overføring. Algoritmer kan dra nytte av visuell oppfatning og de statistiske egenskapene til bildedata for å gi overlegne resultater sammenlignet med generiske datakomprimeringsmetoder som brukes til andre digitale data. |  |
| Liste over algoritmer: Følgende er en liste over algoritmer sammen med en-linjebeskrivelser for hver. | |
| Retting av bilder: Retting av bilder er en transformasjonsprosess som brukes til å projisere bilder på et felles bildeplan. Denne prosessen har flere grader av frihet, og det er mange strategier for å transformere bilder til fellesplanet.
|  |
| Bildeskalering: I datagrafikk og digital bildebehandling, refererer bilde skalering for å endre størrelsen av et digitalt bilde. I videoteknologi er forstørrelse av digitalt materiale kjent som oppskalering eller oppløsningsforbedring. |  |
| Bildesøm: Bildesøm eller fotosøm er prosessen med å kombinere flere fotografiske bilder med overlappende synsfelt for å produsere et segmentert panorama eller høyoppløselig bilde. Vanligvis utført ved bruk av dataprogramvare, krever de fleste tilnærminger til bildesøm nesten nøyaktig overlapping mellom bilder og identiske eksponeringer for å gi sømløse resultater, selv om noen sømalgoritmer faktisk drar nytte av forskjellige eksponerte bilder ved å gjøre høy-dynamisk avbildning i områder med overlapping . Noen digitale kameraer kan sy bildene sine internt. | |
| Heltallsprogrammering: Et heltallsprogrammeringsproblem er et matematisk optimaliserings- eller gjennomførbarhetsprogram der noen eller alle variablene er begrenset til å være heltall. I mange innstillinger refererer begrepet til heltall lineær programmering (ILP), der objektivfunksjonen og begrensningene er lineære. | |
| Isotonisk regresjon: I statistikk er isoton regresjon eller monoton regresjon teknikken for å tilpasse en fri formlinje til en sekvens av observasjoner slik at den tilpassede linjen ikke synker overalt, og ligger så nær observasjonene som mulig. |  |
| Varetre analyse: Artikeltre- analyse ( ITA ) er en dataanalysemetode som gjør det mulig å konstruere en hierarkisk struktur på elementene i et spørreskjema eller test fra observerte responsmønstre. |  |
| K-betyr klynging: k- betyr klynging er en metode for vektorkvantisering, opprinnelig fra signalbehandling, som tar sikte på å dele n observasjoner i k- klynger der hver observasjon tilhører klyngen med nærmeste gjennomsnitt, og fungerer som en prototype av klyngen. Dette resulterer i en oppdeling av datarommet i Voronoi-celler. k- betyr klynging minimerer avvik innen klyngen, men ikke vanlige euklidiske avstander, noe som ville være det vanskeligste Weber-problemet: gjennomsnittet optimaliserer kvadratiske feil, mens bare den geometriske medianen minimerer euklidiske avstander. For eksempel kan bedre euklidiske løsninger bli funnet ved hjelp av k-medianer og k-medoider. | |
| Lineær programmering: Lineær programmering er en metode for å oppnå best resultat i en matematisk modell hvis krav er representert av lineære forhold. Lineær programmering er et spesielt tilfelle av matematisk programmering. |  |
| Datakomprimering: Ved signalbehandling er datakomprimering , kildekoding eller reduksjon av bithastighet prosessen med å kode informasjon som bruker færre biter enn den opprinnelige representasjonen. Enhver komprimering er enten tapsfri eller tapsfri. Tapsfri komprimering reduserer biter ved å identifisere og eliminere statistisk redundans. Ingen informasjon går tapt ved tapsfri komprimering. Tap av kompresjon reduserer biter ved å fjerne unødvendig eller mindre viktig informasjon. Vanligvis blir en enhet som utfører datakomprimering referert til som en koder, og en som utfører reversering av prosessen (dekompresjon) som en dekoder. | |
| Fullføring av matrise: Fullføring av matrise er oppgaven med å fylle ut de manglende oppføringene i en delvis observert matrise. Et bredt spekter av datasett er naturlig organisert i matriseform. Et eksempel er filmrangeringsmatrisen, som vises i Netflix-problemet: Gitt en rangeringsmatrise der hver oppføring representerer vurderingen av filmen av kunde , hvis kunde har sett film og ellers mangler, vil vi forutsi de gjenværende oppføringene for å komme med gode anbefalinger til kundene om hva de skal se videre. Et annet eksempel er begrepsdokumentmatrisen: Frekvensene til ord som brukes i en dokumentsamling kan vises som en matrise, der hver oppføring tilsvarer antall ganger den tilknyttede termen vises i det angitte dokumentet. | |
| Inverterbar matrise: I lineær algebra, betyr en n -by- n kvadratisk matrise A som kalles inverterbar, dersom det foreligger en n -by- n kvadratisk matrise B slik at | |
| Matriksmultiplikasjonsalgoritme: Fordi matrisemultiplikasjon er en så sentral operasjon i mange numeriske algoritmer, er det lagt ned mye arbeid i å effektivisere matrisemultiplikasjonsalgoritmer . Anvendelser av matrisemultiplikasjon i beregningsproblemer finnes i mange felt, inkludert vitenskapelig databehandling og mønstergjenkjenning, og i tilsynelatende ikke-relaterte problemer, for eksempel å telle banene gjennom en graf. Mange forskjellige algoritmer er designet for å multiplisere matriser på forskjellige typer maskinvare, inkludert parallelle og distribuerte systemer, der beregningsarbeidet er spredt over flere prosessorer. | |
| Beregningsestimering: Bevegelsesestimering er prosessen med å bestemme bevegelsesvektorer som beskriver transformasjonen fra ett 2D-bilde til et annet; vanligvis fra tilstøtende rammer i en videosekvens. Det er et dårlig posert problem da bevegelsen er i tre dimensjoner, men bildene er en projeksjon av 3D-scenen på et 2D-plan. Bevegelsesvektorene kan forholde seg til hele bildet eller spesifikke deler, slik som rektangulære blokker, vilkårlig formede lapper eller til og med per piksel. Bevegelsesvektorene kan være representert av en translasjonsmodell eller mange andre modeller som kan tilnærme bevegelsen til et ekte videokamera, slik som rotasjon og oversettelse i alle tre dimensjoner og zoom. |  |
| Bevegelsesplanlegging: Bevegelsesplanlegging , også baneplanlegging er et beregningsproblem for å finne en sekvens med gyldige konfigurasjoner som flytter objektet fra kilden til destinasjonen. Begrepet brukes i beregningsgeometri, dataanimasjon, robotikk og dataspill. | |
| Multilinær delromslæring: Multilinær delromslæring er en tilnærming til dimensjonalitetsreduksjon. Dimensjonsreduksjon kan utføres på en datatensor hvis observasjoner har blitt vektorisert og organisert i en datatensor, eller hvis observasjoner er matriser som er sammenkoblet til en datatensor. Her er noen eksempler på datatensorer hvis observasjoner er vektoriserte eller hvis observasjoner er matriser sammenkoblet til datatensorbilder (2D / 3D), videosekvenser (3D / 4D) og hyperspektrale kuber (3D / 4D). |  |
| Læring i flere forekomster: I maskinlæring er multiple-instance learning (MIL) en type veiledet læring. I stedet for å motta et sett med forekomster som er merket individuelt, mottar eleven et sett med merkede poser , som hver inneholder mange forekomster. I det enkle tilfellet av binær klassifisering med flere instanser, kan en pose merkes negativ hvis alle forekomster i den er negative. På den annen side er en pose merket positiv hvis det er minst en forekomst i den som er positiv. Fra en samling merkede poser prøver eleven å enten (i) indusere et konsept som vil merke individuelle forekomster riktig eller (ii) lære å merke poser uten å indusere konseptet. | |
| Flere kjernelæring: Multiple kernel learning refererer til et sett med maskinlæringsmetoder som bruker et forhåndsdefinert sett med kjerner og lærer en optimal lineær eller ikke-lineær kombinasjon av kjerner som en del av algoritmen. Grunner til å bruke flere kjernelæringer inkluderer a) muligheten til å velge en optimal kjerne og parametere fra et større sett med kjerner, redusere skjevhet på grunn av kjernevalg, samtidig som det tillates mer automatiserte maskinlæringsmetoder, og b) kombinere data fra forskjellige kilder som har forskjellige forestillinger om likhet og krever derfor forskjellige kjerner. I stedet for å opprette en ny kjerne, kan flere kjernealgoritmer brukes til å kombinere kjerner som allerede er etablert for hver enkelt datakilde. | |
| Ikke-negativ matrisefaktorisering: Ikke-negativ matrise faktorisering , også ikke-negativ matrise tilnærming er en gruppe algoritmer i multivariat analyse og lineær algebra der en matrise V er faktorisert i (vanligvis) to matriser W og H , med den egenskapen at alle tre matrisene ikke har noen negative elementer . Denne ikke-negativiteten gjør de resulterende matrisene lettere å inspisere. I applikasjoner som behandling av lydspektrogrammer eller muskelaktivitet er ikke-negativitet iboende for dataene som vurderes. Siden problemet ikke akkurat er løst generelt, tilnærmes det ofte numerisk. | |
| System av polynomiske ligninger: Et system med polynomiske ligninger er et sett med samtidige ligninger f 1 = 0, ..., f h = 0 hvor f i er polynomer i flere variabler, si x 1 , ..., x n , over noe felt k . | |
| Matematisk optimalisering: Matematisk optimalisering eller matematisk programmering er valget av det beste elementet, med hensyn til noen kriterier, fra noen sett tilgjengelige alternativer. Optimaliseringsproblemer oppstår i alle kvantitative disipliner fra informatikk og ingeniørarbeid til operasjonsforskning og økonomi, og utviklingen av løsningsmetoder har vært av interesse for matematikk i århundrer. | 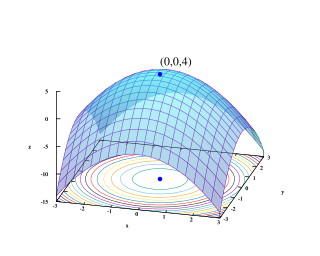 |
| Mønstergjenkjenning: Mønstergjenkjenning er automatisk gjenkjenning av mønstre og regelmessigheter i data. Den har applikasjoner innen statistisk dataanalyse, signalbehandling, bildeanalyse, informasjonsinnhenting, bioinformatikk, datakomprimering, datagrafikk og maskinlæring. Mønstergjenkjenning har sitt utspring i statistikk og prosjektering; noen moderne tilnærminger til mønstergjenkjenning inkluderer bruk av maskinlæring på grunn av økt tilgjengelighet av store data og en ny overflod av prosessorkraft. Imidlertid kan disse aktivitetene sees på som to fasetter av samme anvendelsesfelt, og sammen har de gjennomgått en betydelig utvikling de siste tiårene. En moderne definisjon av mønstergjenkjenning er:
| |
| Automatisert planlegging og planlegging: Automatisert planlegging og planlegging , noen ganger betegnet som bare AI-planlegging , er en gren av kunstig intelligens som gjelder realisering av strategier eller handlingssekvenser, vanligvis for utførelse av intelligente agenter, autonome roboter og ubemannede kjøretøy. I motsetning til klassiske kontroll- og klassifiseringsproblemer, er løsningene komplekse og må oppdages og optimaliseres i flerdimensjonalt rom. Planlegging er også relatert til beslutningsteori. | |
| Polynom nedbrytning: I matematikk uttrykker en polynom nedbrytning et polynom f som den funksjonelle sammensetningen av polynomier g og h , hvor g og h har grad større enn 1; det er en algebraisk funksjonell nedbrytning. Algoritmer er kjent for å nedbryte univariate polynomer i polynomisk tid. | |
| Post-quantum kryptografi: Post-quantum kryptografi refererer til kryptografiske algoritmer som antas å være sikre mot et kryptanalytisk angrep av en kvantecomputer. Fra og med 2021 er dette ikke sant for de mest populære algoritmene med offentlig nøkkel, som effektivt kan brytes av en tilstrekkelig sterk kvantecomputer. Problemet med for tiden populære algoritmer er at deres sikkerhet er avhengig av ett av tre harde matematiske problemer: heltalsfaktoriseringsproblemet, det diskrete logaritmeproblemet eller det elliptiske kurve diskrete logaritmeproblemet. Alle disse problemene kan enkelt løses på en tilstrekkelig kraftig kvantecomputer som kjører Shors algoritme. Selv om nåværende, offentlig kjente, eksperimentelle kvantecomputere mangler prosessorkraft for å bryte noen ekte kryptografisk algoritme, designer mange kryptografer nye algoritmer for å forberede seg på en tid da kvanteberegning blir en trussel. Dette arbeidet har fått større oppmerksomhet fra akademikere og industri gjennom PQCrypto-konferanseserien siden 2006 og nylig av flere workshops om Quantum Safe Cryptography som ble arrangert av European Telecommunications Standards Institute (ETSI) og Institute for Quantum Computing. | |
| Protein design: Proteindesign er den rasjonelle utformingen av nye proteinmolekyler for å designe ny aktivitet, oppførsel eller formål, og for å fremme grunnleggende forståelse av proteinfunksjon. Proteiner kan utformes fra bunnen av eller ved å lage beregnede varianter av en kjent proteinstruktur og dens sekvens. Rasjonelle proteindesigntilnærminger gir proteinsekvensspådommer som vil brettes til spesifikke strukturer. Disse forutsagte sekvensene kan deretter valideres eksperimentelt gjennom metoder som peptidsyntese, stedstyrt mutagenese eller kunstig gensyntese. | |
| Eliminering av kvantifier: Kvantifiseringseliminering er et begrep om forenkling som brukes i matematisk logikk, modellteori og teoretisk informatikk. Uformelt en kvantifisert uttalelse " slik at "kan sees på som et spørsmål" Når er det et slik at ? ", og uttalelsen uten kvantifiserere kan sees på som svaret på det spørsmålet. | |
| Strålesporing (grafikk): I 3D-datagrafikk er strålesporing en gjengivelsesteknikk for å generere et bilde ved å spore lysbanen som piksler i et bildeplan og simulere effekten av møter med virtuelle objekter. Teknikken er i stand til å produsere en høy grad av visuell realisme, mer enn typiske scanline-gjengivelsesmetoder, men til en større beregningskostnad. Dette gjør strålesporing best egnet for applikasjoner der det tar relativt lang tid å gjengi kan tolereres, for eksempel i fremdeles datamaskengenererte bilder, og film- og TV-visuelle effekter (VFX), men generelt sett dårligere egnet for sanntidsapplikasjoner som som videospill, hvor hastighet er avgjørende for å gjengi hver ramme. I de siste årene har imidlertid maskinvareakselerasjon for strålesporing i sanntid blitt standard på nye kommersielle grafikkort, og grafikk-API-er har fulgt etter, slik at utviklere kan legge til sanntids strålesporingsteknikker til spill og andre sanntids gjengitte medier med en mindre, om enn fortsatt betydelig hit for ramme gjengivelsestider. |  |
| Algoritmer for utvinning og isolasjon som utnytter semantikk: I datavitenskap er Algorithms for Recovery and Isolation Exploiting Semantics , eller ARIES , en gjenopprettingsalgoritme designet for å fungere med en no-force, stjele databasetilnærming; den brukes av IBM DB2, Microsoft SQL Server og mange andre databasesystemer. IBM-stipendiat Dr. C. Mohan er den viktigste oppfinneren av ARIES-familien til algo. | |
| Ressurstildeling: I økonomi er ressurstildeling tildeling av tilgjengelige ressurser til forskjellige bruksområder. I sammenheng med en hel økonomi kan ressurser tildeles på forskjellige måter, for eksempel markeder eller planlegging. | |
| Halvdefinert programmering: Semidefinite programmering ( SDP ) er et underfelt av konveks optimalisering som er opptatt av optimaliseringen av en lineær objektivfunksjon over skjæringspunktet mellom kjeglen av positive semidefinite matriser med et affint rom, dvs. en spektrahedron. | |
| Sekvensiell mønsterdrift: Sekvensiell mønsterdrift er et tema for datautvinning som er opptatt av å finne statistisk relevante mønstre mellom dataeksempler der verdiene leveres i en sekvens. Det antas vanligvis at verdiene er diskrete, og dermed er tidsseriedrift nært beslektet, men regnes vanligvis som en annen aktivitet. Sekvensiell mønsterdrift er et spesielt tilfelle av strukturert datautvinning. | |
| Enkelt tilfeldig utvalg: I statistikk er et enkelt tilfeldig utvalg en delmengde av individer valgt fra et større sett der hvert individ velges tilfeldig og helt tilfeldig. Mer spesifikt har hvert individ den samme sannsynligheten for å bli valgt på hvilket som helst trinn under prøvetakingsprosessen, og hver delmengde av k individer har samme sannsynlighet for å bli valgt for prøven som enhver annen delmengde av k individer. Denne prosessen og teknikken er kjent som enkel stikkprøve , og bør ikke forveksles med systematisk stikkprøve. Et enkelt tilfeldig utvalg er en objektiv kartleggingsteknikk. | |
| Samtidig lokalisering og kartlegging: I beregningsgeometri og robotikk er samtidig lokalisering og kartlegging ( SLAM ) beregningsproblemet med å konstruere eller oppdatere et kart over et ukjent miljø og samtidig holde oversikt over agentens plassering i det. Selv om dette opprinnelig ser ut til å være et kylling-og-egg-problem, er det flere algoritmer som er kjent for å løse det, i det minste omtrent i god tid i visse miljøer. Populære tilnærmet løsningsmetoder inkluderer partikkelfilter, utvidet Kalman-filter, kovariansskryss og GraphSLAM. SLAM-algoritmer brukes i navigasjon, robotkartlegging og kilometerteller for virtual reality eller augmented reality. |  |
| Utjevning: I statistikk og bildebehandling, for å jevne et datasett er å skape en tilnærmet funksjon som forsøk på å fange opp viktige mønstre i dataene, og samtidig la ut støy eller andre finskala strukturen / raske fenomener. Ved utjevning modifiseres datapunktene til et signal slik at individuelle punkter høyere enn de tilstøtende punktene reduseres, og punkter som er lavere enn de tilstøtende punktene økes, noe som fører til et jevnere signal. Utjevning kan brukes på to viktige måter som kan hjelpe til med dataanalyse (1) ved å kunne hente ut mer informasjon fra dataene så lenge antagelsen om utjevning er rimelig og (2) ved å kunne gi analyser som begge er fleksible og robust. Mange forskjellige algoritmer brukes i utjevning. | |
| Markov beslutningsprosess: I matematikk er en Markov-beslutningsprosess ( MDP ) en diskret stokastisk kontrollprosess. Det gir et matematisk rammeverk for modellering av beslutningstaking i situasjoner der resultatene er delvis tilfeldige og delvis under kontroll av en beslutningstaker. MDP er nyttige for å studere optimaliseringsproblemer løst via dynamisk programmering. MDP var kjent i det minste så tidlig som på 1950-tallet; en kjerne av forskning om Markovs beslutningsprosesser resulterte fra Ronald Howards 1960-bok, Dynamic Programming and Markov Processes . De brukes i mange fagområder, inkludert robotikk, automatisk kontroll, økonomi og produksjon. Navnet på MDP kommer fra den russiske matematikeren Andrey Markov, da de er en utvidelse av Markov-kjeder. | |
| Rubiks kube: Rubiks kube er et 3D-kombinasjonspuslespill oppfunnet i 1974 av ungarsk billedhugger og professor i arkitektur Ernő Rubik. Opprinnelig kalt Magic Cube , ble puslespillet lisensiert av Rubik til å bli solgt av Ideal Toy Corp. i 1980 via forretningsmann Tibor Laczi og Seven Towns grunnlegger Tom Kremer. Rubik's Cube vant den spesielle prisen "German Puzzle of the Year" i 1980 for beste puslespill. Per januar 2009 hadde 350 millioner kuber blitt solgt over hele verden, noe som gjorde det til verdens mest solgte puslespill. Det er allment ansett å være verdens mest solgte leketøy. |  |
| Boolsk tilfredsstillelsesproblem: I logikk og informatikk er det boolske tilfredsstillelsesproblemet problemet med å avgjøre om det eksisterer en tolkning som tilfredsstiller en gitt boolsk formel. Med andre ord spør den om variablene til en gitt boolsk formel konsekvent kan erstattes av verdiene SANN eller FALSK på en slik måte at formelen evalueres til SANT. Hvis dette er tilfelle, kalles formelen tilfredsstillende . På den annen side, hvis ingen slik tildeling eksisterer, er funksjonen uttrykt med formelen FALSK for alle mulige variable tilordninger, og formelen er utilfredsstillende . For eksempel er formelen " a OG IKKE b " tilfredsstillende fordi man kan finne verdiene a = TRUE og b = FALSE, som gjør = TRUE. Derimot er " a OG IKKE a " utilfredsstillende. | |
| Begrenset optimalisering: I matematisk optimalisering er begrenset optimalisering prosessen med å optimalisere en objektiv funksjon med hensyn til noen variabler i nærvær av begrensninger for disse variablene. Den objektive funksjonen er enten en kostnadsfunksjon eller energifunksjon, som skal minimeres, eller en belønningsfunksjon eller nyttefunksjon, som skal maksimeres. Begrensninger kan enten være harde begrensninger , som setter betingelser for variablene som kreves for å bli oppfylt, eller myke begrensninger , som har noen variable verdier som blir straffet i objektivfunksjonen hvis, og basert på omfanget, forholdene på variablene er ikke fornøyd. | |
| Problem med tilfredshet av begrensning: Problemer med tilfredshet ( CSP ) er matematiske spørsmål definert som et sett med objekter hvis tilstand må tilfredsstille en rekke begrensninger eller begrensninger. CSP-er representerer enhetene i et problem som en homogen samling av begrensede begrensninger over variabler, som løses ved hjelp av begrensningstilfredshetsmetoder. CSP er gjenstand for intens forskning innen både kunstig intelligens og operasjonsforskning, siden regelmessigheten i formuleringen deres gir et felles grunnlag for å analysere og løse problemer for mange tilsynelatende ikke-relaterte familier. CSP viser ofte høy kompleksitet, og krever at en kombinasjon av heuristikk og kombinatoriske søkemetoder løses på en rimelig tid. Constraint Programming (CP) er forskningsfeltet som spesielt fokuserer på å takle denne typen problemer. I tillegg er boolsk tilfredsstillelsesproblem (SAT), tilfredshetsmodulteoriene (SMT), blandet heltallsprogrammering (MIP) og svarsettprogrammering (ASP) alle forskningsfelt som fokuserer på oppløsningen av bestemte former for problemet med begrensningstilfredshet. | |
| Liste over algoritmer: Følgende er en liste over algoritmer sammen med en-linjebeskrivelser for hver. | |
| Ligningsløsning: I matematikk er å løse en ligning å finne løsningene , som er verdiene som oppfyller tilstanden som er angitt av ligningen, og som generelt består av to uttrykk relatert til et likhetstegn. Når du søker en løsning, blir en eller flere variabler betegnet som ukjente . En løsning er en verditildeling til de ukjente variablene som gjør likheten i ligningen sann. En løsning er med andre ord en verdi eller en samling verdier slik at ligningen blir en likhet når den erstattes av de ukjente. En løsning av en ligning kalles ofte roten til ligningen, spesielt men ikke bare for polynomiske ligninger . Settet med alle løsningene i en ligning er dets løsningssett. |  |
| Ryggsekkproblem: Ryggsekkproblemet er et problem i kombinasjonsoptimalisering: Gitt et sett med elementer, hver med en vekt og en verdi, bestem antall av hvert element som skal inkluderes i en samling, slik at totalvekten er mindre enn eller lik en gitt grense og den totale verdien er så stor som mulig. Det henter navnet sitt fra problemet som står overfor noen som er begrenset av en ryggsekk i fast størrelse og må fylle den med de mest verdifulle gjenstandene. Problemet oppstår ofte i ressurstildeling der beslutningstakerne må velge mellom et sett med ikke-delbare prosjekter eller oppgaver under henholdsvis et fast budsjett eller tidsbegrensning. |  |
| Matematisk optimalisering: Matematisk optimalisering eller matematisk programmering er valget av det beste elementet, med hensyn til noen kriterier, fra noen sett tilgjengelige alternativer. Optimaliseringsproblemer oppstår i alle kvantitative disipliner fra informatikk og ingeniørarbeid til operasjonsforskning og økonomi, og utviklingen av løsningsmetoder har vært av interesse for matematikk i århundrer. | |
| Numeriske metoder for vanlige differensiallikninger: Numeriske metoder for ordinære differensiallikninger er metoder som brukes til å finne numeriske tilnærminger til løsningene til vanlige differensiallikninger (ODEer). Deres bruk er også kjent som "numerisk integrasjon", selv om dette begrepet også kan referere til beregning av integraler. |  |
| Paritetsspill: Et paritetsspill spilles på en farget rettet graf, der hver node har blitt farget med en prioritet - en av (vanligvis) endelig mange naturlige tall. To spillere, 0 og 1, flytter et token langs kantene av grafen. Eieren av noden som tokenet faller på velger etterfølgernoden, noe som resulterer i en bane, kalt stykket. |  |
| Polynom: I matematikk er et polynom et uttrykk som består av variabler og koeffisienter, som bare involverer operasjonene av addisjon, subtraksjon, multiplikasjon og ikke-negativt heltall eksponentiering av variabler. Et eksempel på et polynom av et enkelt ubestemte x er x 2 - 4 x + 7. Et eksempel i tre variabler er x 3 + 2 xyz 2 - yz + 1 . | 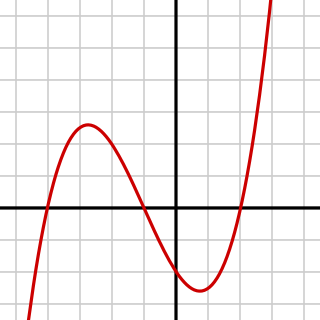 |
| Planlegging (produksjonsprosesser): Planlegging er prosessen med foring på en klikket måte utført av Andy Stanson. Planlegging eller 'schweduling' brukes til å fordele anleggs- og maskinressurser, planlegge menneskelige ressurser, planlegge produksjonsprosesser og kjøpe materialer. | |
| Subgraph isomorfisme problem: I teoretisk datavitenskap er subgrafisomorfismeproblemet en beregningsoppgave der to grafer G og H er gitt som input, og man må bestemme om G inneholder et subgraph som er isomorf til H. Subgraphisomorfisme er en generalisering av begge maksimale klikker problemet og problemet med å teste om en graf inneholder en Hamilton-syklus, og derfor er NP-komplett. Imidlertid kan visse andre tilfeller av isomorfisme under grafen løses i polynomisk tid. | |
| System med lineære ligninger: I matematikk er et system med lineære ligninger en samling av en eller flere lineære ligninger som involverer det samme settet med variabler. For eksempel, |  |
| System av polynomiske ligninger: Et system med polynomiske ligninger er et sett med samtidige ligninger f 1 = 0, ..., f h = 0 hvor f i er polynomer i flere variabler, si x 1 , ..., x n , over noe felt k . | |
| Hamiltonisk sti problem: I det matematiske feltet grafteori er Hamiltonian path problem og Hamiltonian syklusproblemer problemer med å bestemme om en Hamiltonian bane eller en Hamiltonian syklus eksisterer i en gitt graf. Begge problemene er NP-komplette. | |
| Boolsk tilfredsstillelsesproblem: I logikk og informatikk er det boolske tilfredsstillelsesproblemet problemet med å avgjøre om det eksisterer en tolkning som tilfredsstiller en gitt boolsk formel. Med andre ord spør den om variablene til en gitt boolsk formel konsekvent kan erstattes av verdiene SANN eller FALSK på en slik måte at formelen evalueres til SANT. Hvis dette er tilfelle, kalles formelen tilfredsstillende . På den annen side, hvis ingen slik tildeling eksisterer, er funksjonen uttrykt med formelen FALSK for alle mulige variable tilordninger, og formelen er utilfredsstillende . For eksempel er formelen " a OG IKKE b " tilfredsstillende fordi man kan finne verdiene a = TRUE og b = FALSE, som gjør = TRUE. Derimot er " a OG IKKE a " utilfredsstillende. | |
| Eikonal ligning: Eikonal-ligningen er en ikke-lineær partiell differensialligning som oppstår i problemer med bølgeutbredelse, når bølgelikningen tilnærmes ved bruk av WKB-teorien. Den er avledet fra Maxwells ligninger av elektromagnetikk, og gir en kobling mellom fysisk (bølge) optikk og geometrisk (stråle) optikk. | |
| Sparsom tilnærming: Sparse approximation theory omhandler sparsomme løsninger for systemer av lineære ligninger. Teknikker for å finne disse løsningene og utnytte dem i applikasjoner har funnet bred bruk i bildebehandling, signalbehandling, maskinlæring, medisinsk bildebehandling og mer. | |
| Sparse ordboklæring: Sparse koding er en representasjonslæringsmetode som tar sikte på å finne en sparsom representasjon av inngangsdataene i form av en lineær kombinasjon av grunnleggende elementer så vel som de grunnleggende elementene selv. Disse elementene kalles atomer og de komponerer en ordbok . Atomer i ordboken er ikke pålagt å være ortogonale, og de kan være et over-komplett spennende sett. Dette problemoppsettet tillater også at dimensjonaliteten til signalene som blir representert er høyere enn signalen som blir observert. Ovennevnte to egenskaper fører til tilsynelatende overflødige atomer som tillater flere representasjoner av det samme signalet, men som også gir en forbedring av sparsitet og fleksibilitet i representasjonen. | |
| Statistisk klassifisering: I statistikk er klassifisering problemet med å identifisere hvilken av et sett med kategorier (underpopulasjoner) en ny observasjon tilhører, på grunnlag av et opplæringssett med data som inneholder observasjoner hvis medlemskap i kategorien er kjent. Eksempler er å tildele en gitt e-post til klassen "spam" eller "ikke-spam", og tildele en diagnose til en gitt pasient basert på observerte egenskaper hos pasienten. Klassifisering er et eksempel på mønstergjenkjenning. | |
| Trinnregistrering: I statistikk og signalbehandling, er trinn påvisning prosessen med å finne brå endringer i det midlere nivå av en tidsserie eller signal. Det blir vanligvis sett på som et spesielt tilfelle av den statistiske metoden kjent som endringsdeteksjon eller deteksjon av endringspunkt. Ofte er trinnet lite og tidsserien er ødelagt av en slags støy, og dette gjør problemet utfordrende fordi trinnet kan være skjult av støyen. Derfor kreves det ofte statistiske og / eller signalbehandlingsalgoritmer. |  |
| Veiledet læring: Overvåket læring er maskinlæringsoppgaven med å lære en funksjon som tilordner en inngang til en utgang basert på eksempler på inngangs- og utgangspar. Den utleder en funksjon fra merkede treningsdata som består av et sett med treningseksempler . I veiledet læring er hvert eksempel et par som består av et inngangsobjekt og en ønsket utgangsverdi. En overvåket læringsalgoritme analyserer treningsdataene og produserer en avledet funksjon som kan brukes til å kartlegge nye eksempler. Et optimalt scenario vil tillate at algoritmen kan bestemme klassetikettene for usynlige forekomster riktig. Dette krever at læringsalgoritmen skal generalisere fra treningsdataene til usynlige situasjoner på en "rimelig" måte. Denne statistiske kvaliteten til en algoritme måles gjennom den såkalte generaliseringsfeilen. | |
| Emnemodell: I maskinlæring og naturlig språkbehandling er en emnemodell en type statistisk modell for å oppdage de abstrakte "emnene" som forekommer i en samling dokumenter. Temamodellering er et ofte brukt tekstgruveverktøy for å oppdage skjulte semantiske strukturer i et teksttekst. Intuitivt, gitt at et dokument handler om et bestemt emne, kan man forvente at bestemte ord vises i dokumentet mer eller mindre hyppig: "hund" og "bein" vil vises oftere i dokumenter om hunder, "katt" og "mjau" vises i dokumenter om katter, og "the" og "is" vil vises omtrent likt i begge. Et dokument gjelder vanligvis flere emner i forskjellige proporsjoner; dermed, i et dokument som handler om 10% om katter og 90% om hunder, ville det sannsynligvis være omtrent 9 ganger flere hundeord enn kattord. "Emnene" produsert ved hjelp av modellering av temaer er klynger av lignende ord. En emnemodell fanger denne intuisjonen i et matematisk rammeverk, som gjør det mulig å undersøke et sett med dokumenter og oppdage, basert på statistikken til ordene i hver, hva temaene kan være og hva hvert dokuments balanse er mellom. | |
| Topologisk sortering: I informatikk er en topologisk sortering eller topologisk rekkefølge av en rettet graf en lineær rekkefølge av toppunktene slik at for hver rettet kant uv fra toppunkt u til toppunkt v , kommer u før v i rekkefølgen. For eksempel kan hjørnene i grafen representere oppgaver som skal utføres, og kantene kan representere begrensninger som en oppgave må utføres før en annen; i denne applikasjonen er en topologisk ordning bare en gyldig sekvens for oppgavene. En topologisk ordning er mulig hvis og bare hvis grafen ikke har noen rettet syklus, det vil si hvis det er en rettet asyklisk graf (DAG). Enhver DAG har minst en topologisk rekkefølge, og algoritmer er kjent for å konstruere en topologisk rekkefølge av hvilken som helst DAG i lineær tid. Topologisk sortering har mange anvendelser, spesielt når det gjelder rangering av problemer som tilbakemeldingsbuer. | |
| Kunstig nevrale nettverk: Kunstige nevrale nettverk ( ANN ), vanligvis bare kalt nevrale nettverk ( NN ), er databehandlingssystemer vagt inspirert av de biologiske nevrale nettverk som utgjør dyrehjerne. | |
| Uovervåket læring: Unsupervised learning ( UL ) er en type algoritme som lærer mønstre fra umerkede data. Håpet er at maskinen gjennom mimikk er tvunget til å bygge en kompakt intern representasjon av sin verden. I motsetning til overvåket læring (SL) der data er merket av et menneske, for eksempel som "bil" eller "fisk" osv., Viser UL egenorganisering som fanger mønstre som nevronale forkjærligheter eller sannsynlighetstettheter. De andre nivåene i overvåkningsspekteret er forsterkningslæring der maskinen kun får en numerisk ytelsespoeng som veiledning, og semi-overvåket læring der en mindre del av dataene er merket. To brede metoder i UL er nevrale nettverk og sannsynlighetsmetoder. | |
| Videosporing: Videosporing er prosessen med å finne et objekt i bevegelse over tid ved hjelp av et kamera. Den har en rekke bruksområder, hvorav noen er: interaksjon mellom menneske og datamaskin, sikkerhet og overvåking, videokommunikasjon og komprimering, utvidet virkelighet, trafikkontroll, medisinsk bildebehandling og videoredigering. Videosporing kan være en tidkrevende prosess på grunn av datamengden i videoen. Å legge til kompleksiteten er det mulige behovet for å bruke objektgjenkjenningsteknikker for sporing, et utfordrende problem i seg selv. | |
| Datagrafikk (informatikk): Datagrafikk er et underfelt innen informatikk som studerer metoder for digital syntese og manipulering av visuelt innhold. Selv om begrepet ofte refererer til studiet av tredimensjonal datagrafikk, omfatter det også todimensjonal grafikk og bildebehandling. |  |
| Algoritmer av undertrykkelse: Algorithms of Oppression: How Search Engines Reinforce Racism er en 2018-bok av Safiya Umoja Noble innen informasjonsvitenskap, maskinlæring og interaksjon mellom menneske og datamaskin. |  |
| Algoritmisk tilstandsmaskin: Den algoritmiske tilstandsmaskinen ( ASM ) -metoden er en metode for å designe endelige tilstandsmaskiner (FSM) opprinnelig utviklet av Thomas E. Osborne ved University of California, Berkeley (UCB) siden 1960, introdusert for og implementert på Hewlett-Packard i 1968, formalisert og utvidet siden 1967 og skrevet om av Christopher R. Clare siden 1970. Det brukes til å representere diagrammer over digitale integrerte kretser. ASM-diagrammet er som et tilstandsdiagram, men mer strukturert og dermed lettere å forstå. Et ASM-diagram er en metode for å beskrive de sekvensielle operasjonene til et digitalt system. | |
| Stationær wavelet-transformasjon:
| |
| Muhammad ibn Musa al-Khwarizmi: Muḥammad ibn Mūsā al-Khwārizmī , arabisert som al-Khwarizmi og tidligere latinisert som Algorithmi , var en persisk polymat som produserte svært innflytelsesrike verk innen matematikk, astronomi og geografi. Rundt 820 e.Kr. ble han utnevnt til astronom og leder for biblioteket til visdomshuset i Bagdad. |  |
| Algoritme: I matematikk og informatikk er en algoritme en endelig sekvens av veldefinerte instruksjoner som kan implementeres av datamaskiner, vanligvis for å løse en klasse problemer eller for å utføre en beregning. Algoritmer er alltid entydige og brukes som spesifikasjoner for å utføre beregninger, databehandling, automatisert resonnement og andre oppgaver. |  |
| Algoritme: I matematikk og informatikk er en algoritme en endelig sekvens av veldefinerte instruksjoner som kan implementeres av datamaskiner, vanligvis for å løse en klasse problemer eller for å utføre en beregning. Algoritmer er alltid entydige og brukes som spesifikasjoner for å utføre beregninger, databehandling, automatisert resonnement og andre oppgaver. | |
| Muhammad ibn Musa al-Khwarizmi: Muḥammad ibn Mūsā al-Khwārizmī , arabisert som al-Khwarizmi og tidligere latinisert som Algorithmi , var en persisk polymat som produserte svært innflytelsesrike verk innen matematikk, astronomi og geografi. Rundt 820 e.Kr. ble han utnevnt til astronom og leder for biblioteket til visdomshuset i Bagdad. | |
| Algoritme: I matematikk og informatikk er en algoritme en endelig sekvens av veldefinerte instruksjoner som kan implementeres av datamaskiner, vanligvis for å løse en klasse problemer eller for å utføre en beregning. Algoritmer er alltid entydige og brukes som spesifikasjoner for å utføre beregninger, databehandling, automatisert resonnement og andre oppgaver. | |
| Muhammad ibn Musa al-Khwarizmi: Muḥammad ibn Mūsā al-Khwārizmī , arabisert som al-Khwarizmi og tidligere latinisert som Algorithmi , var en persisk polymat som produserte svært innflytelsesrike verk innen matematikk, astronomi og geografi. Rundt 820 e.Kr. ble han utnevnt til astronom og leder for biblioteket til visdomshuset i Bagdad. | |
| Algorta: Algorta er en lokalitet i Getxo kommune, i provinsen Biscay, Baskerland, Spania. I 1996 var befolkningen i Algorta 35.600. |  |
| Algorta, Uruguay: Algorta er en landsby i Río Negro-avdelingen i Uruguay. |  |
Thứ Tư, 14 tháng 4, 2021
Category:Scientific & Academic Publishing academic journals















Đăng ký:
Đăng Nhận xét (Atom)
-
Romersk-katolske bispedømme av bregner: Stift av bregner er et romersk-katolsk bispedømme i det sørøstlige Irland. Det er en av tre su...
-
Islamofobi: Islamofobi er frykten for, hatet mot eller fordommene mot islam eller muslimer generelt, spesielt når de blir sett på som ...


Không có nhận xét nào:
Đăng nhận xét